| 主菜单 |
数据挖掘模型是包含运行特定数据挖掘任务所需全部设置的模型。
为什么?数据挖掘对查找和描述特定多维数据集中的隐藏模式非常有用。 随着多维数据集中的数据迅速增长,手动查找信息变得非常困难。数据挖掘提供的算法允许自动模式查找及交互式分析。管理员现在可以在将要训练数据的 Analysis Services 中设置数据挖掘模型。然后用户可以使用 ISV 客户端工具对受训数据运行高级分析。 |
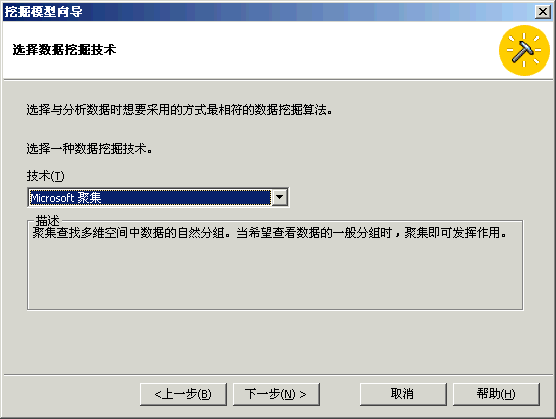
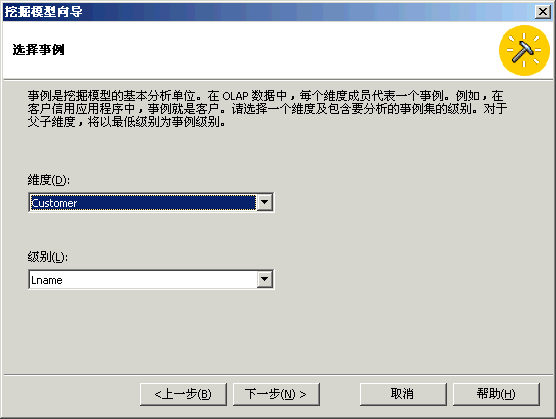
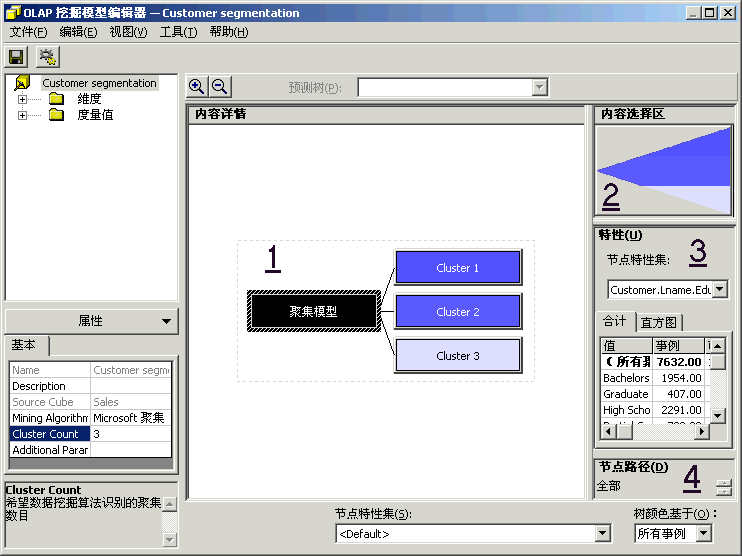
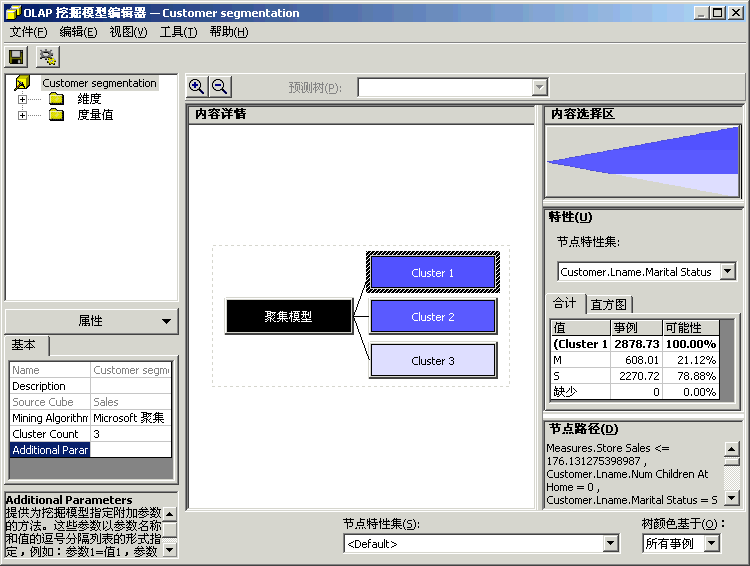
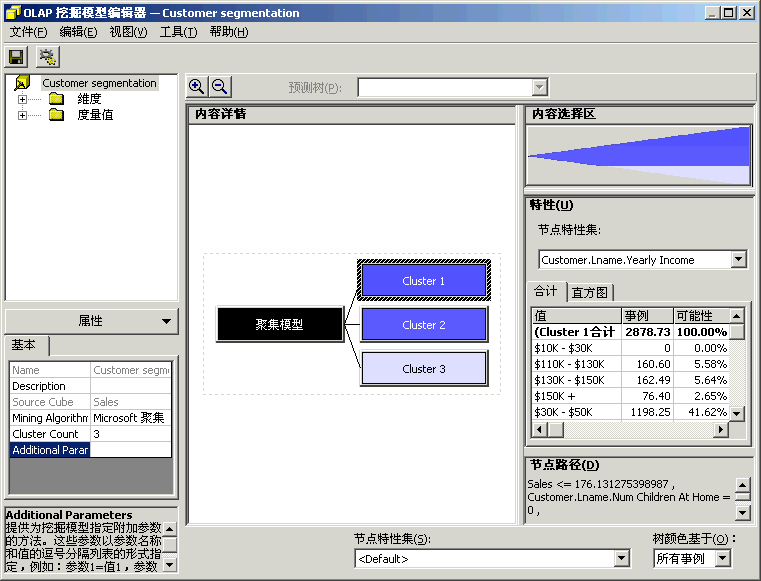
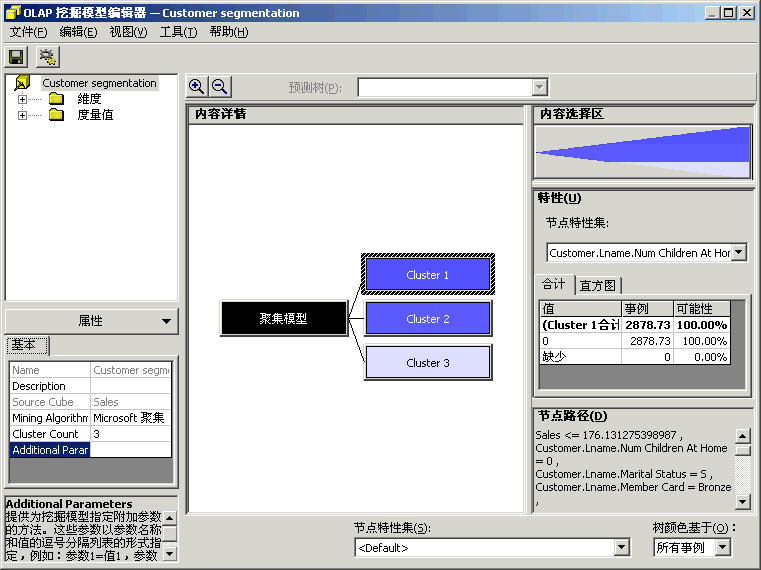
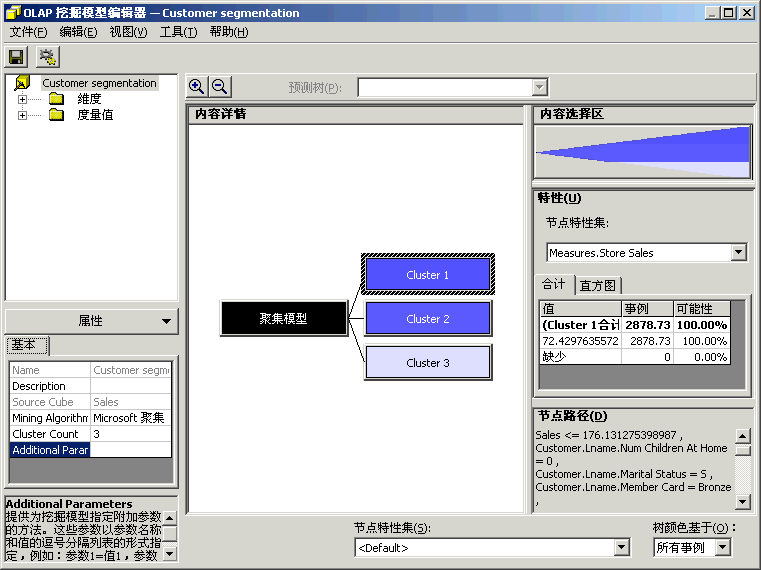
方案:市场部想增加客户满意度和客户保有率。于是实行了两个创造性的方法以达到这些目标。对会员卡方案重新进行定义,以便更好地为客户提供服务并且使所提供的服务能够更加密切地满足客户的期望。创办《每周赠券》杂志,将杂志送给客户群,以鼓励他们访问 FoodMart 商店。我们在上一章讲述了如何使用“Microsoft 决策树”算法重新定义会员卡方案。 为了定义《每周赠券》杂志,市场部想将客户群划分为三个类别。事实上,市场部已有创建三个版本的《每周赠券》杂志的财政预算。市场部想对销售数据运行一些数据挖掘进程,以便识别三个组中的客户。根据三个组的特征,市场部可以选择赠券的类型,以便插入各个版本的《每周赠券》杂志。市场部还将能够知道哪一类客户应该接收哪一个版本的杂志。 本节将创建第二个数据挖掘模型,此模型将使用“Microsoft 聚集”算法将客户群划分为三个类别。请将客户设置为要调查的维度(事例维度)。然后将 Store Sales(商店销售)度量值设置为数据挖掘算法划分 Customer(客户)维度所用信息。接下来,请选择想要在算法中表示各个客户类别特性的人口统计特征列表:婚姻状况、年收入、在家子女数、教育程度…… 然后训练此模型,最终使其能够浏览受训数据并从中分析三种客户类别。市场部将根据每个客户类别的人口统计属性,选择将要插入《每周赠券》杂志各个版本中的赠券列表。 |
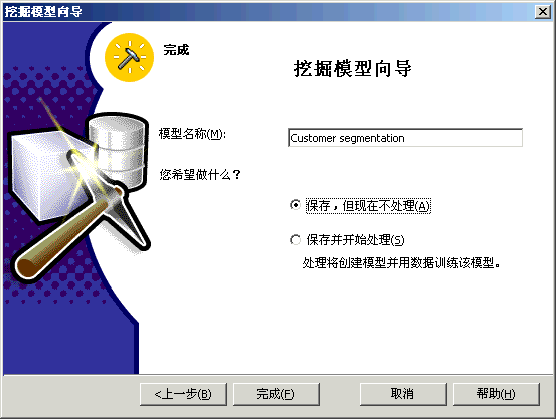
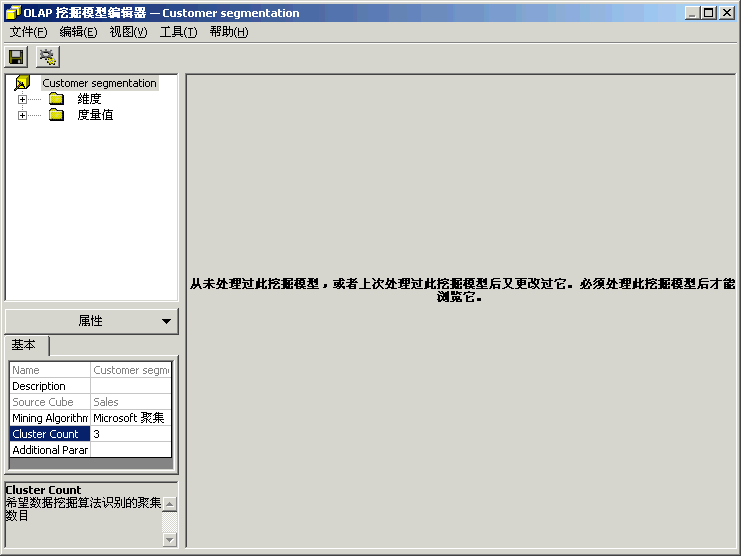
注意: 处理数据挖掘模型可能会花费一些时间。
| 主菜单 |